Von Kevin Lapagna und Dominik Wotruba, Red Hat
Wir alle kennen IoT-Geräte, die direkt mit Cloud-Diensten verbunden sind. Neben den Smart Devices, die heute unser Zuhause bereichern, sind es vor allem unsere Mobiltelefone, die im Wesentlichen dieser Architektur folgen. Es gibt aber auch Anwendungsfälle, in denen ein solches Konzept suboptimal oder sogar unmöglich ist. Folgende Kriterien können dafür ausschlaggebend sein:
- Verfügbarkeit: Je nach Standort und Anbindung kann es vorkommen, dass eine Internetverbindung in Ausnahmefällen oder sogar regelmässig nicht zur Verfügung steht. Anwendungsfälle, die eine höhere Verfügbarkeit als diese Verbindung erfordern, benötigen Alternativen.
- Latenz: Eine Anfrage an ein Cloud-Rechenzentrum zu senden, zu verarbeiten und wieder zurückzusenden, führt zu Laufzeiten, die durch die zwischengeschalteten Geräte und nicht zuletzt durch physikalische Eigenschaften begrenzt sind. Grosse Schwankungen im Laufzeitverhalten können ebenfalls problematisch sein. Anwendungsfälle, die jitterfreie Antworten im Sub-Millisekundenbereich benötigen, können von der Cloud kaum profitieren.
- Durchsatz: Edge-Sensoren werden immer vielfältiger und präziser. Beispielsweise kann eine einzige hochauflösende Hochgeschwindigkeitskamera für die Qualitätskontrolle in einer Fertigungsanlage innerhalb von Sekunden Gigabytes an Daten erzeugen. Die Übertragung aller anfallenden Daten in die Cloud kann daher eine grosse Herausforderung darstellen und hohe Kosten verursachen.
- Kosten: Infrastruktur und Datentransfers in der Cloud können hohe Kosten verursachen. Lokale Datenverarbeitung kann die wirtschaftlichere Wahl sein, insbesondere bei hoher Auslastung und spezifischen Hardwareanforderungen (z.B. GPUs).
- Sicherheit: Aus datenschutzrechtlichen oder regulatorischen Gründen kann es unerwünscht oder sogar verboten sein, bestimmte Daten ungefiltert oder überhaupt in die Cloud zu übertragen.
Kurzum, viele Betriebe brauchen bereits heute oder künftig vermehrt Lösungen, um Daten dort zu verarbeiten, wo sie generiert werden; bei IoT-Geräten, Sensoren, Steuerungen, Produktionslinien etc. Diese Art von lokaler Datenverarbeitung nennen wir Edge-Computing. Es gibt verschiedene Auslegungen des Begriffs, aber der Einfachheit halber nennen wir im weiteren Verlauf alles Edge, was nicht in einem klassischen Rechenzentrum betrieben wird.
Dieses IT/OT-Umfeld (Operational Technology) ist heute oft noch von traditionellen, um nicht zu sagen überholten Prozessen und Technologien geprägt. Dabei werden jedoch viele der Vorteile und Konzepte, welche moderne Umgebungen in Rechenzentren und der Cloud heute ausmachen, häufig nicht berücksichtigt und sind kaum zu finden.
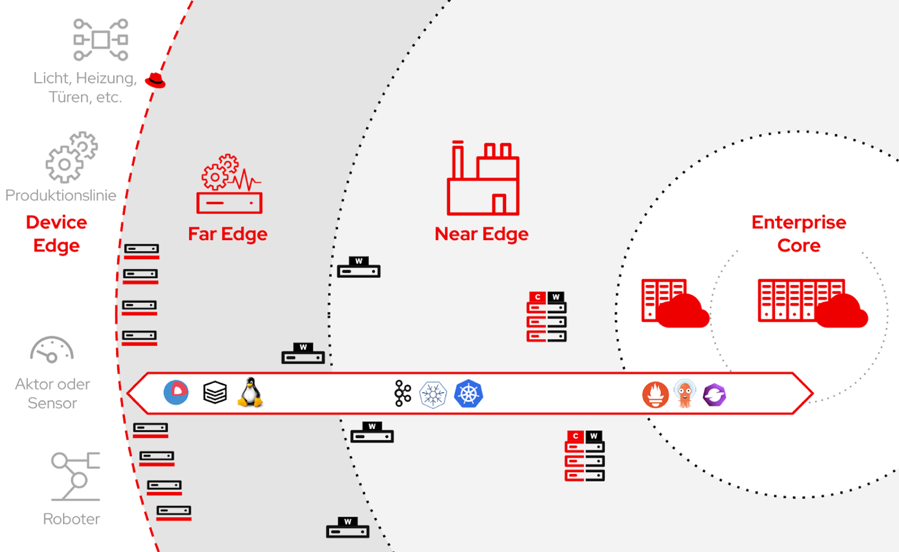
Die Open-Source-Welt bietet bereits heute alle Lösungsbausteine (Red Hat)
Weniger Aufwand – mehr Sicherheit
Es kann Unternehmen enorme Vorteile bringen, diese Edge-Umgebungen zu modernisieren, um in Zukunft neue, innovative Anwendungsfälle schnell und flexibel umzusetzen. Bei der Verwaltung von traditionellen Systemen können durch Automatisierung und Standardisierung die Aufwände und die damit verbundenen Kosten stark gesenkt werden, und als willkommener Nebeneffekt wird oft die Sicherheit signifikant erhöht. Dazu kommt meist eine Beschleunigung der Abläufe, was insbesondere bei produzierenden Betrieben durch kürzere bzw. ganz ausbleibende Serviceunterbrüche bei Wartungsfenstern die Kapazität erhöhen kann.
Ziel ist nun aber nicht, wieder eine wilde Mischung neuer Technologien verschiedener Hersteller ins vorhandene Flickwerk einzuweben, sondern dieselben Kerntechnologien und Plattformen zu nutzen, auf welche sich die moderne IT-Welt bereits eingeschworen hat – und diese basieren alle fast ausnahmslos auf Open Source.
Red Hat hat in den vergangenen Jahren zusammen mit der Open-Source-Community viel Aufwand betrieben, die erfolgreichsten Technologien aus dem Rechenzentrum und Cloud-Bereich fixfertig konsumierbar in das Enterprise-Edge-Umfeld zu bringen. Intention dabei ist aber nicht eine schlichte Modernisierung des bestehenden Software-Stacks, sondern die Möglichkeit, damit einige der wertvollsten Eigenschaften moderner IT ins Edge-Umfeld zu holen. Beispielsweise:
- Deklarativ: Infrastruktur und Anwendungen werden nicht mehr manuell auf den Systemen verwaltet. Stattdessen beschreibt ein zentrales Text-Repository den gewünschten Zustand, und die Umgebung verwaltet sich selbst dahingehend, diesen Zustand zu erreichen.
- Versioniert: Alles in einem solchen System ist strikt versioniert und getrackt, inklusive der Konfiguration. Der Zustand des Gesamtsystems ist jederzeit bekannt und kann notfalls zurückgerollt oder in kürzester Zeit komplett neu aufgebaut werden.
- Automatisiert: Wartezeiten gibt es nur noch bei gewünschten manuellen Checkpoints. Die Realisierung der gewünschten Änderungen werden systemübergreifend durchautomatisiert.
- Immutable: Alles ausser Nutzdaten ist im Read-Only-Modus gehalten. Unerwünschte Abweichungen einzelner Systeme und Konfigurationen sind nicht möglich.
- Hochverfügbar: Anwendungen müssen nicht mehr an ein physisches oder virtuelles System gekoppelt sein. Sie können dynamisch skaliert oder gar aktualisiert werden, ohne einen Serviceunterbruch zu verursachen.
- Verbunden: Alle Services, welche miteinander kommunizieren müssen, können dies über dezentrale, aber einheitliche Schnittstellen standortübergreifend auf sichere Art und Weise.
- Self-Service: Die effektiven Nutzer der Infrastruktur oder Services können, im Rahmen strikter digital gesetzter Leitplanken, jegliche Services sofort selbst erstellen und verwalten.
Einheitliche Werkzeuge
Der grösste Vorteil, dies mit etablierten Open-Source-Lösungen umzusetzen, liegt aber nicht nur in den dazugewonnenen Fähigkeiten im Edge-Umfeld an sich, sondern darin, dass man die Möglichkeit hat, die Gesamtheit aller Workloads mit denselben Werkzeugen in einer einheitlichen oder gar zusammengeführten Ansicht zu verwalten: Von der riesigen Webapplikation in der Public-Cloud bis zum kleinsten Sensorüberwachungsprozess am Förderband. Die Datensammlung und -verarbeitung direkt bei Edge-Geräten wird damit stark vereinfacht.
Eine kontinuierliche Aggregation, um z.B. Machine-Learning-Modelle in der Cloud zu trainieren, ist damit ebenso möglich wie das daraus resultierende skalierbare Ausrollen dieser KI/ML-Modelle zurück in eine Vielzahl von Diensten im Produktionsbereich.
Fazit
Durch einheitliche Werkzeuge und Technologien können Fachkräfte effizienter und teamübergreifend zusammenarbeiten, um mit weniger Aufwand mehr zu erreichen. Zudem reduzieren diese Technologien das Risiko eines proprietären Vendor-Lock-Ins und ermöglichen so auch in Zukunft den kontinuierlichen Zugang zur innovativsten Quelle moderner IT: der Open-Source-Community.